A Simple PDF to PNG server
Also works for DOCX, XLSX, etc
What are the Top 500,000 Websites?
Alexa Internet creates a list of the top 1,000,000 sites on the web. It’s updated daily, and best of all it’s free.
Use Google’s Cache to crawl sites
Some websites implement certain measures to prevent bots from crawling them, with varying degrees of sophistication. Getting around those measures can be difficult and tricky, and may sometimes require special infrastructure. Please consider contacting commercial support if in doubt.
Here are some tips to keep in mind when dealing with these kinds of sites:
- rotate your user agent from a pool of well-known ones from browsers (google around to get a list of them)
- disable cookies (see
<span class="pre">COOKIES_ENABLED</span>) as some sites may use cookies to spot bot behaviour- use download delays (2 or higher). See
<span class="pre">DOWNLOAD_DELAY</span>setting.- if possible, use Google cache to fetch pages, instead of hitting the sites directly
- use a pool of rotating IPs. For example, the free Tor project or paid services like ProxyMesh. An open source alternative is scrapoxy, a super proxy that you can attach your own proxies to.
- use a highly distributed downloader that circumvents bans internally, so you can just focus on parsing clean pages. One example of such downloaders is Crawlera
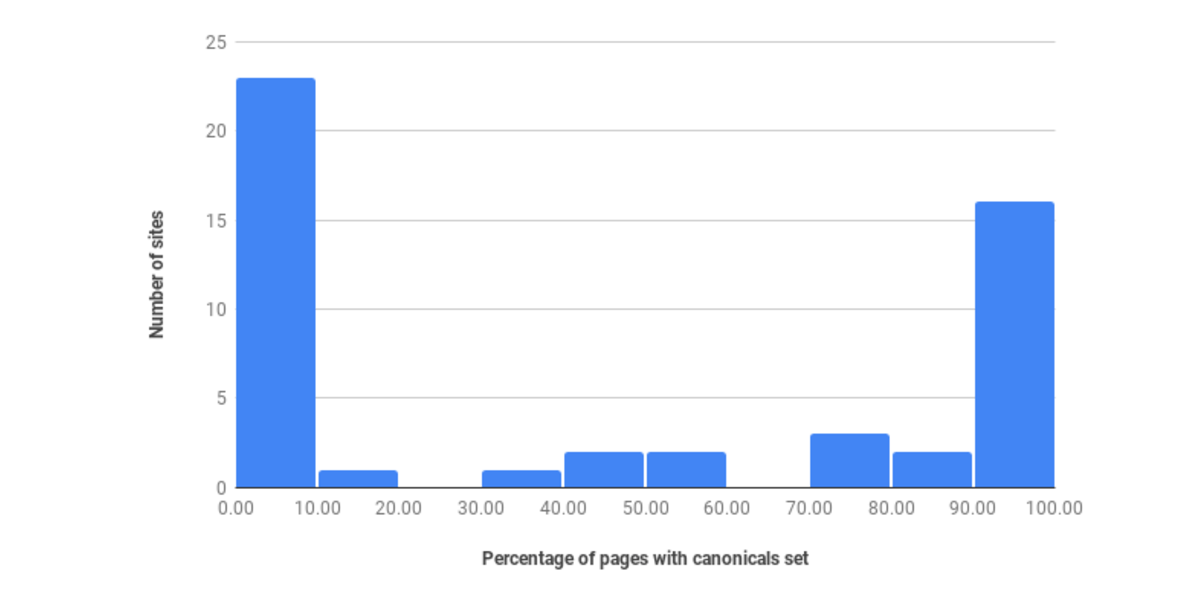
56% of Webpages Don’t Have a Canonical Tag Set
So how many webpages don’t have a canonical tag set?
Based on our research and the data gathered from our site search health reports, we estimate that around 56% of web pages don’t have a canonical set.
This was a quick sampling of only 50 site search health reports, but there’s a clear pattern emerging — sites are either very good at setting their canonicals, or very bad.
We also don’t know how many of the sites have their canonicals set correctly until we start indexing and performing searches on their website. Just because they’re set doesn’t mean they’re necessarily doing the right thing — some websites have every canonical set to the homepage, which defeats the point of even having the tag set.